Description:
Another quick update of my personal Machine Learning project, this sequence diagram illustrates the end-to-end workflow of the system integrated with an API. It showcases how user input (image features) is processed through various components, including the UI, API, and machine learning pipeline, to generate predictions. The diagram also highlights the creation and utilization of supporting files (feedbackData.json and .pkl files) and the interaction with Firebase for storing data.
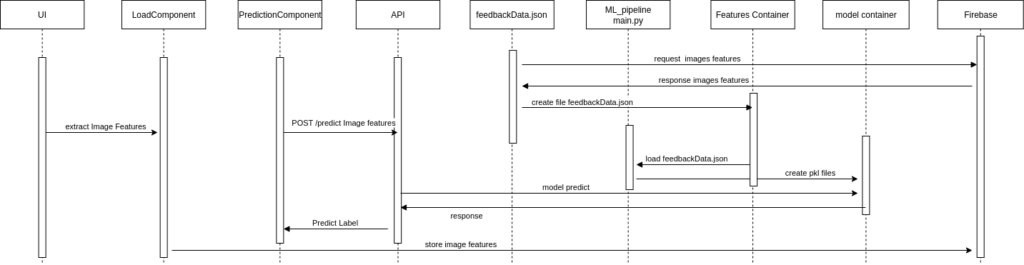
Key Components:
- UI:
- Extracts image features from user input and sends them to the
LoadComponent.
- Extracts image features from user input and sends them to the
- LoadComponent:
- Handles the extraction and preparation of image features for prediction.
- PredictionComponent:
- Sends a POST request to the API with the extracted image features.
- API:
- Receives the POST request, processes the features, and interacts with the machine learning model to predict labels.
- Stores image features and returns the predicted label to the
PredictionComponent.
- feedbackData.json:
- Represents the dataset used for training the machine learning model. It is created and loaded by the ML pipeline.
- ML Pipeline (main.py):
- Processes the dataset (
feedbackData.json) by cleaning, preprocessing, splitting, and training the model. - Saves the trained model and label encoder as
.pklfiles for future use.
- Processes the dataset (
- Features Container:
- Handles the request and response of image features during preprocessing and training.
- Model Container:
- Stores the trained machine learning model and label encoder as
.pklfiles.
- Stores the trained machine learning model and label encoder as
- Firebase:
- Stores predictions or feedback data for further analysis or user interaction.
main.py
from scripts.load_data import load_data
from scripts.clean_data import clean_data
from scripts.preprocess_data import preprocess_data
from scripts.split_data import split_data
from scripts.train_model import train_model
from scripts.evaluate_model import evaluate_model
from sklearn.preprocessing import LabelEncoder
import numpy as np
import joblib
from collections import Counter
from sklearn.metrics import classification_report, confusion_matrix
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent
MODELS_DIR = BASE_DIR / "models"
MODELS_DIR.mkdir(parents=True, exist_ok=True)# Load data
data = load_data('data/feedbackData.json')
# Clean data
cleaned_data = clean_data(data)
# Preprocess data
preprocessed_data, encoder = preprocess_data(cleaned_data)
# Split data
X_train, X_test, y_train, y_test = split_data(preprocessed_data)
#Remove records with missing values
X_train = np.array(X_train)
y_train = np.array(y_train)
# Filter out rows with NaN values
valid_indices = ~np.isnan(X_train).any(axis=1)
X_train = X_train[valid_indices]
y_train = y_train[valid_indices]
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("Any NaN in X_train:", np.isnan(X_train).any())
print("Any NaN in y_train:", np.isnan(y_train).any())
# Train model
clf = train_model(X_train, y_train)
joblib.dump(clf, MODELS_DIR / 'feedback_model.pkl')
print("Saved model to:", MODELS_DIR / "feedback_model.pkl")
# Encode labels and save the encoder
labels = [record["userLabel"] for record in cleaned_data]
encoder = LabelEncoder()
encoded_labels = encoder.fit_transform(labels)
# Save the LabelEncoder
joblib.dump(encoder, MODELS_DIR / "label_encoder.pkl")
print("Saved encoder to:", MODELS_DIR / "label_encoder.pkl")
print("Encoder classes:", list(encoder.classes_))
# Count the occurrences of each label
label_counts = Counter(labels)
print("Label distribution:", label_counts)
# Evaluate the model on the test set
y_pred = clf.predict(X_test)
# Confusion matrix
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
# Classification report
print("Classification Report:")
print(classification_report(y_test, y_pred))
# Evaluate model
evaluate_model(clf, X_test, y_test)Workflow Explanation:
- Feature Extraction:
- The UI extracts image features and sends them to the
LoadComponent.
- The UI extracts image features and sends them to the
- Prediction Request:
- The
PredictionComponentsends the extracted features to the API via a POST request.
- The
- API Processing:
- The API interacts with the trained machine learning model to predict labels based on the input features.
- The API stores the image features and returns the predicted label to the
PredictionComponent.
- ML Pipeline:
- The main.py script processes the dataset (
feedbackData.json) by cleaning, preprocessing, and splitting it into training and testing sets. - The machine learning model is trained and evaluated, and the trained model and label encoder are saved as
.pklfiles.
- The main.py script processes the dataset (
- Firebase Integration:
- Firebase stores predictions or feedback data for further use.
Comments are closed