The Machine Learning Model
On my journey to machine learning every challenge is so excited, my model is able to detect features between apples and pears and after an analysis it back with right label, everything possible because the training process is already in place and tested.
On early test stages I seen that when the images have not remarkable difference that shapes or colors, the model can back with wrong label but if the images have remarkable difference , the model label the image successfully, on that way more varieties the images for training more accurate the model.
I’m so proud of my little app, and this success encourage me to continue on this journey. My next stage is to feed this model with more images and train it intensively to improve his accurate on prediction.
I using 2 different set of images, one for training and another one for tests, in that way I can be sure that the model do label images that it didn’t “seen” before, properly.
As I mentioned before, the model is built on Python, and Github pages hosting only support static pages, so I need to find a hosting for the API that I built.
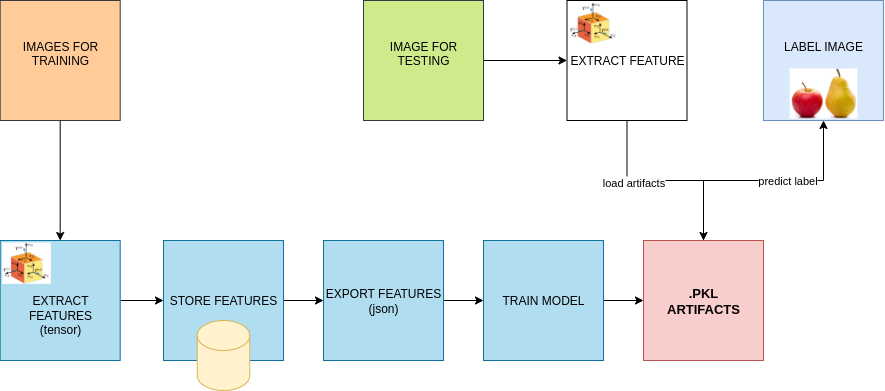
Test Model Process
What test model does:
- Loads artifacts:
- feedback_model.pkl: your trained classifier.
- label_encoder.pkl: the LabelEncoder used during training.
- Loads feature vector to test from data/new_features.json.
- Shapes features to a single sample (1, n_features).
- Predicts the class index with model.predict.
- Decodes the class index back to the original label with encoder.inverse_transform.
- Prints both the raw predicted class (int) and the decoded label (string).
Offline Training Pipeline
It builds the model artifacts of the API uses.
What it does
- Loads the dataset.
- Cleans/normalizes records.
- Extracts features and fits a LabelEncoder on labels.
- Splits into train/test.
- Drops rows with NaNs in features.
- Trains a scikit-learn classifier.
- Saves artifacts: models/feedback_model.pkl and models/label_encoder.pkl.
- Evaluates on the test set (confusion matrix, classification report).

For now the training pipeline works on localhost, but the data load can be done on this URL
Why More and Diverse Data Helps
Feature Representation:
The model learns to distinguish between classes (e.g., apple vs. pear) based on the features extracted from the training data. If the training data contains a wide variety of images for each class (e.g., apples of different colors, shapes, and lighting conditions), the model will generalize better.
Avoiding Overfitting:
If the model is trained on a small dataset, it might overfit to the specific examples it has seen, leading to poor performance on new, unseen data. A larger, more diverse dataset helps the model learn general patterns rather than memorizing specific examples.
Handling Edge Cases:
By including edge cases (e.g., apples that look like pears or vice versa), the model becomes more robust and less likely to make mistakes in ambiguous situations.
Comments are closed