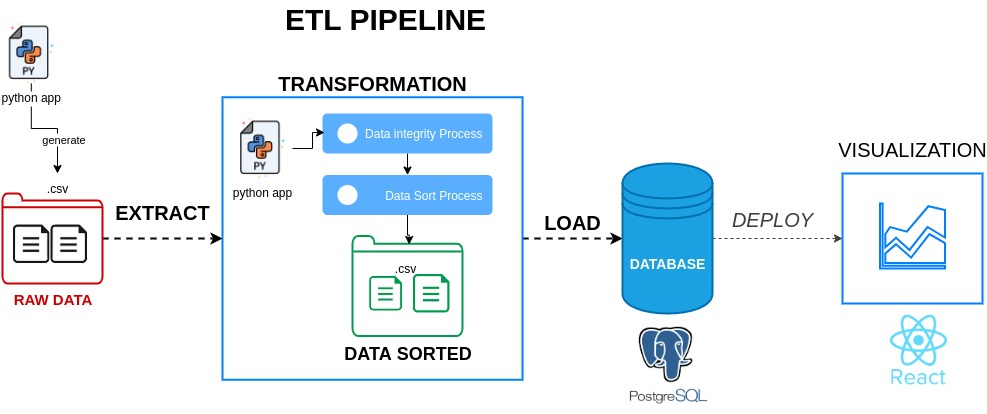
On this stage I faced successfully different challenges and I reached an important milestone reached, I get done the data sorted as part of the data integration process I use for this project, ETL (Extract, Transform, Load), the pipeline is as below:
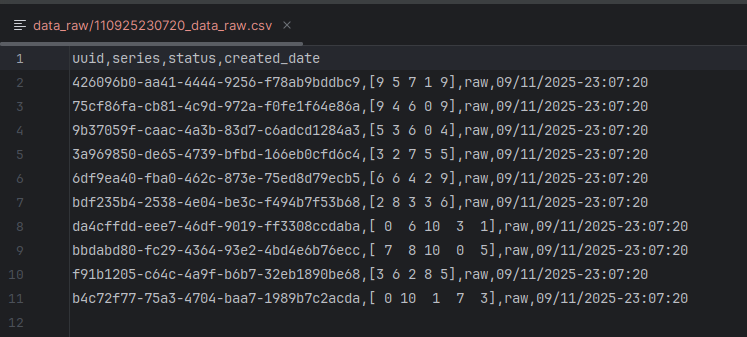
For example, this is a raw data, before transformation
and this is the result after transformation.
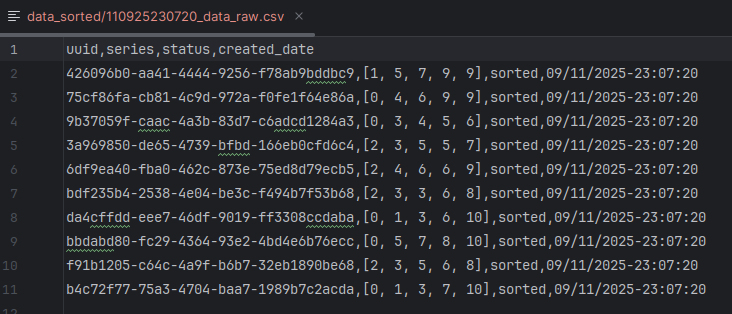
This data is ready to be stored on Database , that is part of the next stage.
Data Integrity
Data integrity refers to the accuracy, consistency, reliability, and completeness of data throughout its entire lifecycle, ensuring it remains trustworthy and uncorrupted.
The process the data integrity is defined as below “Easy Peasy Mac and Cheesy”:
def check_len(series_numbers):
# Check if the series has exactly 5 numbers
if len(series_numbers) != 5:
raise ValueError("Series must contain exactly 5 numbers.")
return True
def check_number_range(series_numbers):
# Check if all numbers are between 0 and 10
for num in series_numbers:
if num < 0 or num > 10:
raise ValueError("Numbers must be between 0 and 10.")
return True
def check_no_empty(series_numbers):
# Check if there are empty values in the line
if "" in series_numbers:
raise ValueError("Line contains empty values.")
return Truedef check_integrity(series_numbers):
# Run all validation checks
try:
check_len(series_numbers)
check_number_range(series_numbers)
check_no_empty(series_numbers)
return True
except ValueError as e:
print(f"Validation error: {e}")
return FalseI’m keeping the raw data in a separate folder as a best practice to ensure data integrity, allow for reprocessing and re-analysis, and enable the discovery of new insights over time. Storing raw data also provides a complete, unbiased source of truth that can be used to rebuild datasets, troubleshoot issues, and adapt analyses to evolving business or research needs.
Key reasons to keep raw data:
- Reproducibility: Having the original, unprocessed data ensures that analyses can be duplicated accurately and independently.
- Error Correction: If errors are found in processed data, the raw data can be used to correct mistakes or adjust the cleaning and analysis pipelines.
- Future Insights: Raw data can be re-analyzed using new techniques or for new purposes that were not foreseen when the data was first collected.
- Data Integrity: Preserving the original data protects against accidental corruption and ensures a reliable, unbiased source for all subsequent operations.
- Troubleshooting: When something goes wrong with processed data or a model, the raw data allows you to trace the issue back to its source.
Updates Committed
The latest changes are committed
Comments are closed